Chapter 3 Modeling Loss Severity
Chapter Preview. The traditional loss distribution approach to modeling aggregate losses starts by separately fitting a frequency distribution to the number of losses and a severity distribution to the size of losses. The estimated aggregate loss distribution combines the loss frequency distribution and the loss severity distribution by convolution. Discrete distributions often referred to as counting or frequency distributions were used in Chapter 2 to describe the number of events such as number of accidents to the driver or number of claims to the insurer. Lifetimes, asset values, losses and claim sizes are usually modeled as continuous random variables and as such are modeled using continuous distributions, often referred to as loss or severity distributions. A mixture distribution is a weighted combination of simpler distributions that is used to model phenomenon investigated in a heterogeneous population, such as modelling more than one type of claims in liability insurance (small frequent claims and large relatively rare claims). In this chapter we explore the use of continuous as well as mixture distributions to model the random size of loss. We present key attributes that characterize continuous models and means of creating new distributions from existing ones. We also explore the effect of coverage modifications, which change the conditions that trigger a payment, such as applying deductibles, limits, or adjusting for inflation, on the distribution of individual loss amounts. The frequency distributions from Chapter 2 will be combined with the ideas from this chapter to describe the aggregate losses over the whole portfolio in Chapter 5.
3.1 Basic Distributional Quantities
In this section we define the basic distributional quantities: moments, percentiles and generating functions.
3.1.1 Moments
Let \(X\) be a continuous random variable with probability density function \(f_{X}\left( x \right)\). The k-th raw moment of \(X\), denoted by \(\mu_{k}^{\prime}\), is the expected value of the k-th power of \(X\), provided it exists. The first raw moment \(\mu_{1}^{\prime}\) is the mean of \(X\) usually denoted by \(\mu\). The formula for \(\mu_{k}^{\prime}\) is given as \[\mu_{k}^{\prime} = \mathrm{E}\left( X^{k} \right) = \int_{0}^{\infty}{x^{k}f_{X}\left( x \right)dx } .\] The support of the random variable \(X\) is assumed to be nonnegative since actuarial phenomena are rarely negative.
The k-th central moment of \(X\), denoted by \(\mu_{k}\), is the expected value of the k-th power of the deviation of \(X\) from its mean \(\mu\). The formula for \(\mu_{k}\) is given as \[\mu_{k} = \mathrm{E}\left\lbrack {(X - \mu)}^{k} \right\rbrack = \int_{0}^{\infty}{\left( x - \mu \right)^{k}f_{X}\left( x \right) dx }.\] The second central moment \(\mu_{2}\) defines the variance of \(X\), denoted by \(\sigma^{2}\). The square root of the variance is the standard deviation \(\sigma\). A further characterization of the shape of the distribution includes its degree of symmetry as well as its flatness compared to the normal distribution. The ratio of the third central moment to the cube of the standard deviation \(\left( \mu_{3} / \sigma^{3} \right)\) defines the coefficient of skewness which is a measure of symmetry. A positive coefficient of skewness indicates that the distribution is skewed to the right (positively skewed). The ratio of the fourth central moment to the fourth power of the standard deviation \(\left(\mu_{4} / \sigma^{4} \right)\) defines the coefficient of kurtosis. The normal distribution has a coefficient of kurtosis of 3. Distributions with a coefficient of kurtosis greater than 3 have heavier tails and higher peak than the normal, whereas distributions with a coefficient of kurtosis less than 3 have lighter tails and are flatter.
Example 3.1.1. SOA Exam Question. Assume that the rv \(X\) has a gamma distribution with mean 8 and skewness 1. Find the variance of \(X\).
Show Example Solution
3.1.2 Quantiles
Percentiles can also be used to describe the characteristics of the distribution of \(X\). The 100pth percentile of the distribution of \(X\), denoted by \(\pi_{p}\), is the value of \(X\) which satisfies \[F_{X}\left( {\pi_{p}}- \right) \leq p \leq F_{X}\left( \pi_{p} \right) ,\] for \(0 \leq p \leq 1\) where \(\pi_{p}-\) refers to the value of X as it increases approaching \(\pi_{p}\) from the left or from below.
The 50-th percentile or the middle point of the distribution, \(\pi_{0.5}\), is the median. Unlike discrete random variables, percentiles of continuous variables are distinct.
Example 3.1.1. SOA Exam Question. Let \(X\) be a continuous random variable with density function \(f_{X}\left( x \right) = \theta e^{- \theta x}\), for \(x > 0\) and 0 elsewhere. If the median of this distribution is \(\frac{1}{3}\), find \(\theta\).
Show Example Solution
3.1.3 Moment Generating Function
The moment generating function, denoted by \(M_{X}\left( t \right)\) uniquely characterizes the distribution of \(X\). While it is possible for two different distributions to have the same moments and yet still differ, this is not the case with the moment generating function. That is, if two random variables have the same moment generating function, then they have the same distribution. The moment generating is a real function whose k-th derivative at zero is equal to the k-th raw moment of \(X\). The moment generating function is given by \[M_{X}\left( t \right) = \mathrm{E}\left( e^{\text{tX}} \right) = \int_{0}^{\infty}{e^{\text{tx}}f_{X}\left( x \right) dx }\] for all \(t\) for which the expected value exists.
Example 3.1.3. SOA Exam Question. The random variable \(X\) has an exponential distribution with mean \(\frac{1}{b}\). It is found that \(M_{X}\left( - b^{2} \right) = 0.2\). Find \(b\).
Show Example Solution
Example 3.1.4. SOA Exam Question. Let \(X_{1}, \ldots, X_{n}\) be independent \(\text{Ga}\left( \alpha_{i},\theta \right)\) random variables. Find the distribution of \(S = \sum_{i = 1}^{n}X_{i}\).
Show Example Solution
3.1.4 Probability Generating Function
The probability generating function, denoted by \(P_{X}\left( z \right)\), also uniquely characterizes the distribution of \(X\). It is defined as \[P_{X}\left( z \right) = \mathrm{E}\left( z^{X} \right) = \int_{0}^{\infty}{z^{x}f_{X}\left( x \right) dx}\] for all \(z\) for which the expected value exists.
We can also use the probability generating function to generate moments of \(X\). By taking the k-th derivative of \(P_{X}\left( z \right)\) with respect to \(z\) and evaluating it at \(z\ = \ 1\), we get \(\mathrm{E}\left\lbrack X\left( X - 1 \right)\cdots\left( X - k + 1 \right) \right\rbrack .\)
The probability generating function is more useful for discrete rvs and was introduced in Section 2.2.2.
3.2 Continuous Distributions for Modeling Loss Severity
In this section we explain the characteristics of distributions suitable for modeling severity of losses, including gamma, Pareto, Weibull and generalized beta distribution of the second kind. Applications for which each distribution may be used are identified.
3.2.1 Gamma Distribution
Recall that the traditional approach in modelling losses is to fit separate models for claim frequency and claim severity. When frequency and severity are modeled separately it is common for actuaries to use the Poisson distribution for claim count and the gamma distribution to model severity. An alternative approach for modelling losses that has recently gained popularity is to create a single model for pure premium (average claim cost) that will be described in Chapter 4.
The continuous variable \(X\) is said to have the gamma distribution with shape parameter \(\alpha\) and scale parameter \(\theta\) if its probability density function is given by \[f_{X}\left( x \right) = \frac{\left( x/ \theta \right)^{\alpha}}{x\Gamma\left( \alpha \right)}\exp \left( -x/ \theta \right) \ \ \ \text{for } x > 0 .\] Note that \(\ \alpha > 0,\ \theta > 0\).
The two panels in Figure 3.1 demonstrate the effect of the scale and shape parameters on the gamma density function.
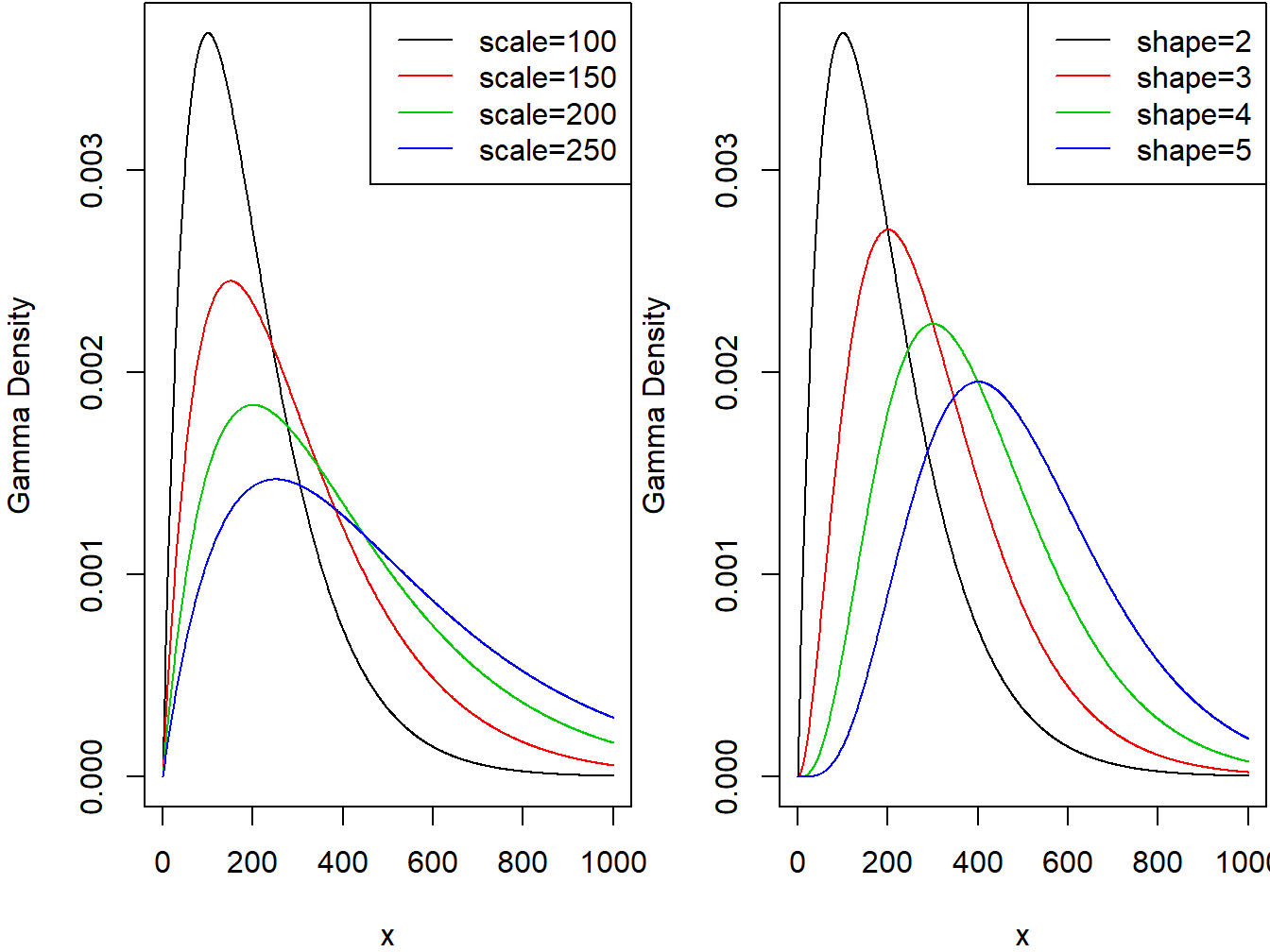
Figure 3.1: Gamma Densities. The left-hand panel is with shape=2 and Varying Scale. The right-hand panel is with scale=100 and Varying Shape.
R Code for Gamma Density Plots
When \(\alpha = 1\) the gamma reduces to an exponential distribution and when \(\alpha = \frac{n}{2}\) and \(\theta = 2\) the gamma reduces to a chi-square distribution with \(n\) degrees of freedom. As we will see in Section 15.4, the chi-square distribution is used extensively in statistical hypothesis testing.
The distribution function of the gamma model is the incomplete gamma function, denoted by \(\Gamma\left(\alpha; \frac{x}{\theta} \right)\), and defined as \[F_{X}\left( x \right) = \Gamma\left( \alpha; \frac{x}{\theta} \right) = \frac{1}{\Gamma\left( \alpha \right)}\int_{0}^{x /\theta}t^{\alpha - 1}e^{- t}\text{dt}\] \(\alpha > 0,\ \theta > 0\). For an integer \(\alpha\), it can be written as \(\Gamma\left( \alpha; \frac{x}{\theta} \right) = 1 - e^{-x/\theta}\sum_{k = 0}^{\alpha-1}\frac{(x/\theta)^k}{k!}\).
The \(k\)-th moment of the gamma distributed random variable for any positive \(k\) is given by \[\mathrm{E}\left( X^{k} \right) = \theta^{k} \frac{\Gamma\left( \alpha + k \right)}{\Gamma\left( \alpha \right)} \ \ \ \text{for } k > 0.\] The mean and variance are given by \(\mathrm{E}\left( X \right) = \alpha\theta\) and \(\mathrm{Var}\left( X \right) = \alpha\theta^{2}\), respectively.
Since all moments exist for any positive \(k\), the gamma distribution is considered a light tailed distribution, which may not be suitable for modeling risky assets as it will not provide a realistic assessment of the likelihood of severe losses.
3.2.2 Pareto Distribution
The Pareto distribution, named after the Italian economist Vilfredo Pareto (1843-1923), has many economic and financial applications. It is a positively skewed and heavy-tailed distribution which makes it suitable for modeling income, high-risk insurance claims and severity of large casualty losses. The survival function of the Pareto distribution which decays slowly to zero was first used to describe the distribution of income where a small percentage of the population holds a large proportion of the total wealth. For extreme insurance claims, the tail of the severity distribution (losses in excess of a threshold) can be modeled using a Pareto distribution.
The continuous variable \(X\) is said to have the Pareto distribution with shape parameter \(\alpha\) and scale parameter \(\theta\) if its pdf is given by \[f_{X}\left( x \right) = \frac{\alpha\theta^{\alpha}}{\left( x + \theta \right)^{\alpha + 1}} \ \ \ x > 0,\ \alpha > 0,\ \theta > 0.\] The two panels in Figure 3.2 demonstrate the effect of the scale and shape parameters on the Pareto density function.
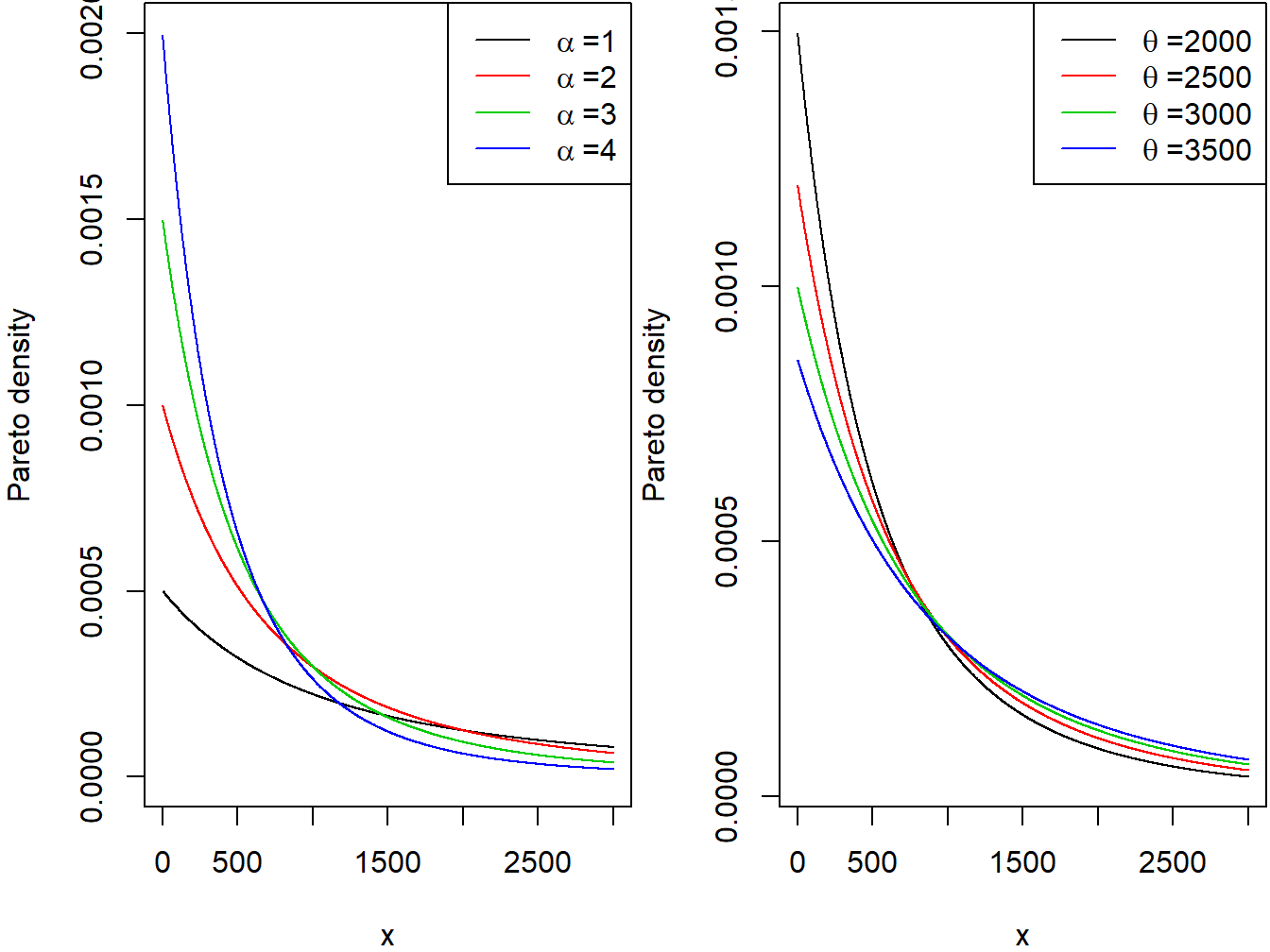
Figure 3.2: Pareto Densities. The left-hand panel is with scale=2000 and Varying Shape. The right-hand panel is with shape=3 and ,Varying Scale
R Code for Pareto Density Plots
The distribution function of the Pareto distribution is given by \[F_{X}\left( x \right) = 1 - \left( \frac{\theta}{x + \theta} \right)^{\alpha} \ \ \ x > 0,\ \alpha > 0,\ \theta > 0.\] It can be easily seen that the hazard function of the Pareto distribution is a decreasing function in \(x\), another indication that the distribution is heavy tailed. The hazard function reveals information about the tail distribution and is often used to model data distributions in survival analysis. The hazard function is defined as the instantaneous potential that the event of interest occurs within a very narrow time frame.
The \(k\)-th moment of the Pareto distributed random variable exists, if and only if, \(\alpha > k\). If \(k\) is a positive integer then \[\mathrm{E}\left( X^{k} \right) = \frac{k!\theta^{k}}{\left( \alpha - 1 \right)\cdots\left( \alpha - k \right)} \ \ \ \alpha > k.\] The mean and variance are given by \[\mathrm{E}\left( X \right) = \frac{\theta}{\alpha - 1} \ \ \ \text{for } \alpha > 1\] and \[\mathrm{Var}\left( X \right) = \frac{\alpha\theta^{2}}{\left( \alpha - 1 \right)^{2}\left( \alpha - 2 \right)} \ \ \ \text{for } \alpha > 2,\]respectively.
Example 3.2.1. The claim size of an insurance portfolio follows the Pareto distribution with mean and variance of 40 and 1800 respectively. Find- The shape and scale parameters.
- The 95-th percentile of this distribution.
Show Example Solution
3.2.3 Weibull Distribution
The Weibull distribution, named after the Swedish physicist Waloddi Weibull (1887-1979) is widely used in reliability, life data analysis, weather forecasts and general insurance claims. Truncated data arise frequently in insurance studies. The Weibull distribution is particularly useful in modeling left-truncated claim severity distributions. Weibull was used to model excess of loss treaty over automobile insurance as well as earthquake inter-arrival times.
The continuous variable \(X\) is said to have the Weibull distribution with shape parameter \(\alpha\) and scale parameter \(\theta\) if its probability density function is given by \[f_{X}\left( x \right) = \frac{\alpha}{\theta}\left( \frac{x}{\theta} \right)^{\alpha - 1} \exp \left(- \left( \frac{x}{\theta} \right)^{\alpha}\right) \ \ \ x > 0,\ \alpha > 0,\ \theta > 0.\] The two panels Figure 3.3 demonstrate the effects of the scale and shape parameters on the Weibull density function.
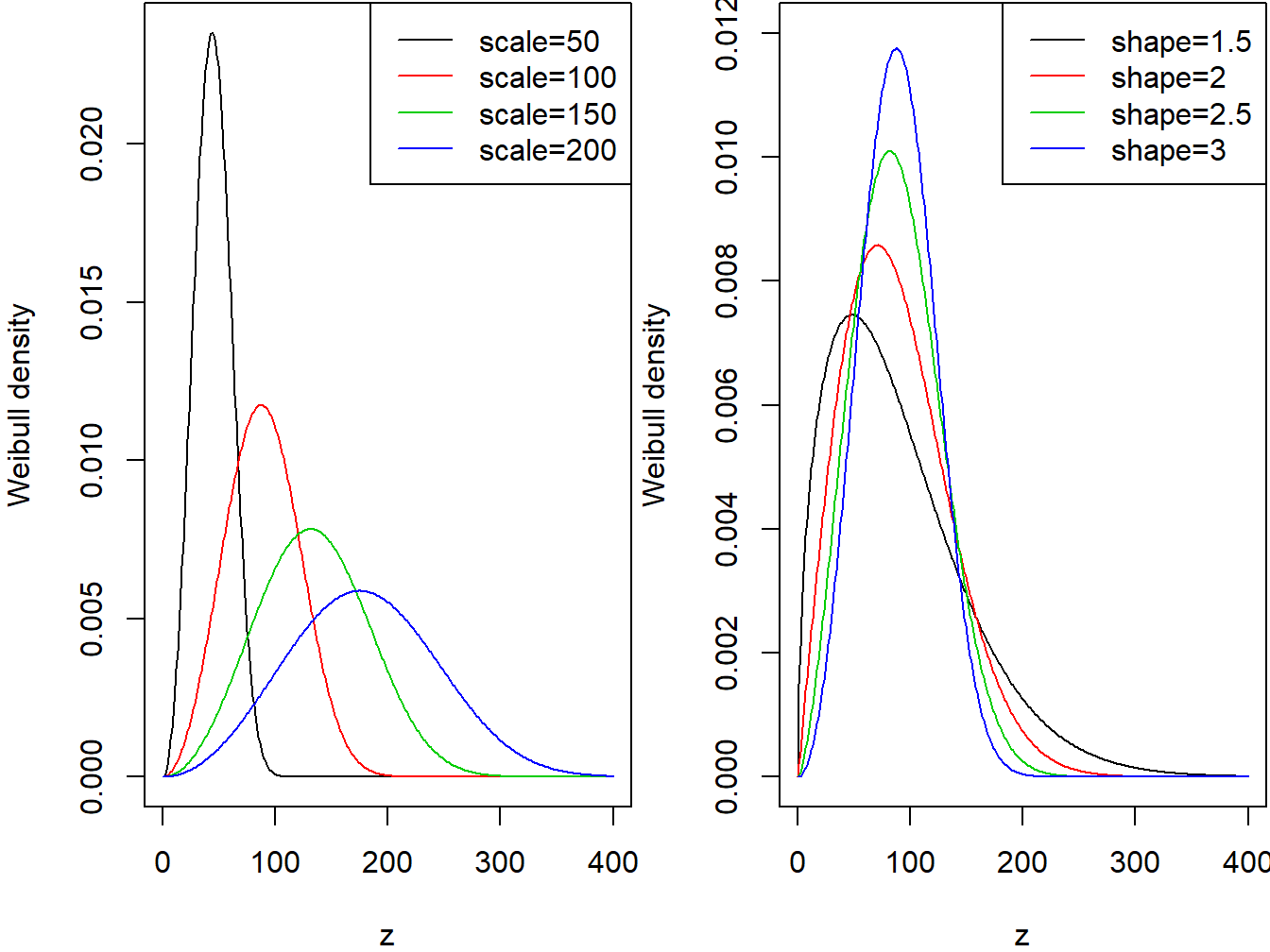
Figure 3.3: Weibull Densities. The left-hand panel is with shape=3 and Varying Scale. The right-hand panel is with scale=100 and Varying Shape.
R Code for Weibull Density Plots
The distribution function of the Weibull distribution is given by \[F_{X}\left( x \right) = 1 - e^{- \left( x / \theta \right)^{\alpha}} \ \ \ x > 0,\ \alpha > 0,\ \theta > 0.\]
It can be easily seen that the shape parameter \(\alpha\) describes the shape of the hazard function of the Weibull distribution. The hazard function is a decreasing function when \(\alpha < 1\), constant when \(\alpha = 1\) and increasing when \(\alpha > 1\). This behavior of the hazard function makes the Weibull distribution a suitable model for a wide variety of phenomena such as weather forecasting, electrical and industrial engineering, insurance modeling and financial risk analysis.
The \(k\)-th moment of the Weibull distributed random variable is given by \[\mathrm{E}\left( X^{k} \right) = \theta^{k}\Gamma\left( 1 + \frac{k}{\alpha} \right) .\]
The mean and variance are given by \[\mathrm{E}\left( X \right) = \theta\Gamma\left( 1 + \frac{1}{\alpha} \right)\] and \[\mathrm{Var}(X)= \theta^{2}\left( \Gamma\left( 1 + \frac{2}{\alpha} \right) - \left\lbrack \Gamma\left( 1 + \frac{1}{\alpha} \right) \right\rbrack ^{2}\right),\] respectively.
Example 3.2.2. Suppose that the probability distribution of the lifetime of AIDS patients (in months) from the time of diagnosis is described by the Weibull distribution with shape parameter 1.2 and scale parameter 33.33.
- Find the probability that a randomly selected person from this population survives at least 12 months,
- A random sample of 10 patients will be selected from this population. What is the probability that at most two will die within one year of diagnosis.
- Find the 99-th percentile of the distribution of lifetimes.
Show Example Solution
3.2.4 The Generalized Beta Distribution of the Second Kind
The Generalized Beta Distribution of the Second Kind (GB2) was introduced by Venter (1983) in the context of insurance loss modeling and by McDonald (1984) as an income and wealth distribution. It is a four-parameter very flexible distribution that can model positively as well as negatively skewed distributions.
The continuous variable \(X\) is said to have the GB2 distribution with parameters \(a\), \(b\), \(\alpha\) and \(\beta\) if its probability density function is given by \[f_{X}\left( x \right) = \frac{ax^{a \alpha - 1}}{b^{a \alpha}B\left( \alpha,\beta \right)\left\lbrack 1 + \left( x/b \right)^{a} \right\rbrack^{\alpha + \beta}} \ \ \ \text{for } x > 0,\] \(a,b,\alpha,\beta > 0\), and where the beta function \(B\left( \alpha,\beta \right)\) is defined as \[B\left( \alpha,\beta \right) = \int_{0}^{1}{t^{\alpha - 1}\left( 1 - t \right)^{\beta - 1}}\text{dt}.\]
The GB2 provides a model for heavy as well as light tailed data. It includes the exponential, gamma, Weibull, Burr, Lomax, F, chi-square, Rayleigh, lognormal and log-logistic as special or limiting cases. For example, by setting the parameters \(a = \alpha = \beta = 1\), then the GB2 reduces to the log-logistic distribution. When \(a = 1\) and \(\beta \rightarrow \infty\), it reduces to the gamma distribution and when \(\alpha = 1\) and \(\beta \rightarrow \infty\), it reduces to the Weibull distribution.
The \(k\)-th moment of the GB2 distributed random variable is given by \[\mathrm{E}\left( X^{k} \right) = \frac{b^{k}\left( \alpha + \frac{k}{a},\beta - \frac{k}{a} \right)}{\left( \alpha,\beta \right)}, \ \ \ k > 0.\] Earlier applications of the GB2 were on income data and more recently have been used to model long-tailed claims data. GB2 was used to model different types of automobile insurance claims, severity of fire losses as well as medical insurance claim data.
3.3 Methods of Creating New Distributions
In this section we
- understand connections among the distributions;
- give insights into when a distribution is preferred when compared to alternatives;
- provide foundations for creating new distributions.
3.3.1 Functions of Random Variables and their Distributions
In Section 3.2 we discussed some elementary known distributions. In this section we discuss means of creating new parametric probability distributions from existing ones. Let \(X\) be a continuous random variable with a known probability density function \(f_{X}(x)\) and distribution function \(F_{X}(x)\). Consider the transformation \(Y = g\left( X \right)\), where \(g(X)\) is a one-to-one transformation defining a new random variable \(Y\). We can use the distribution function technique, the change-of-variable technique or the moment-generating function technique to find the probability density function of the variable of interest \(Y\). In this section we apply the following techniques for creating new families of distributions: (a) multiplication by a constant (b) raising to a power, (c) exponentiation and (d) mixing.
3.3.2 Multiplication by a Constant
If claim data show change over time then such transformation can be useful to adjust for inflation. If the level of inflation is positive then claim costs are rising, and if it is negative then costs are falling. To adjust for inflation we multiply the cost \(X\) by 1+ inflation rate (negative inflation is deflation). To account for currency impact on claim costs we also use a transformation to apply currency conversion from a base to a counter currency.
Consider the transformation \(Y = cX\), where \(c > 0\), then the distribution function of \(Y\) is given by \[F_{Y}\left( y \right) = \Pr\left( Y \leq y \right) = \Pr\left( cX \leq y \right) = \Pr\left( X \leq \frac{y}{c} \right) = F_{X}\left( \frac{y}{c} \right).\] Hence, the probability density function of interest \(f_{Y}(y)\) can be written as \[f_{Y}\left( y \right) = \frac{1}{c}f_{X}\left( \frac{y}{c} \right).\] Suppose that \(X\) belongs to a certain set of parametric distributions and define a rescaled version \(Y\ = \ cX\), \(c\ > \ 0\). If \(Y\) is in the same set of distributions then the distribution is said to be a scale distribution. When a member of a scale distribution is multiplied by a constant \(c\) (\(c > 0\)), the scale parameter for this scale distribution meets two conditions:- The parameter is changed by multiplying by \(c\);
- All other parameters remain unchanged.
Example 3.3.1. SOA Exam Question. The aggregate losses of Eiffel Auto Insurance are denoted in Euro currency and follow a Lognormal distribution with \(\mu = 8\) and \(\sigma = 2\). Given that 1 euro \(=\) 1.3 dollars, find the set of lognormal parameters which describe the distribution of Eiffel’s losses in dollars.
Show Example Solution
Example 3.3.2. SOA Exam Question. Demonstrate that the gamma distribution is a scale distribution.
Show Example Solution
3.3.3 Raising to a Power
In the previous section we talked about the flexibility of the Weibull distribution in fitting reliability data. Looking to the origins of the Weibull distribution, we recognize that the Weibull is a power transformation of the exponential distribution. This is an application of another type of transformation which involves raising the random variable to a power.
Consider the transformation \(Y = X^{\tau}\), where \(\tau > 0\), then the distribution function of \(Y\) is given by \[F_{Y}\left( y \right) = \Pr\left( Y \leq y \right) = \Pr\left( X^{\tau} \leq y \right) = \Pr\left( X \leq y^{1/ \tau} \right) = F_{X}\left( y^{1/ \tau} \right).\]
Hence, the probability density function of interest \(f_{Y}(y)\) can be written as \[f_{Y}(y) = \frac{1}{\tau} y^{1/ \tau - 1} f_{X}\left( y^{1/ \tau} \right).\] On the other hand, if \(\tau < 0\), then the distribution function of \(Y\) is given by \[F_{Y}\left( y \right) = \Pr\left( Y \leq y \right) = \Pr\left( X^{\tau} \leq y \right) = \Pr\left( X \geq y^{1/ \tau} \right) = 1 - F_{X}\left( y^{1/ \tau} \right), \] and \[f_{Y}(y) = \left| \frac{1}{\tau} \right|{y^{1/ \tau - 1}f}_{X}\left( y^{1/ \tau} \right).\]
Example 3.3.3. We assume that \(X\) follows the exponential distribution with mean \(\theta\) and consider the transformed variable \(Y = X^{\tau}\). Show that \(Y\) follows the Weibull distribution when \(\tau\) is positive and determine the parameters of the Weibull distribution.
Show Example Solution
3.3.4 Exponentiation
The normal distribution is a very popular model for a wide number of applications and when the sample size is large, it can serve as an approximate distribution for other models. If the random variable \(X\) has a normal distribution with mean \(\mu\) and variance \(\sigma^{2}\), then \(Y = e^{X}\) has lognormal distribution with parameters \(\mu\) and \(\sigma^{2}\). The lognormal random variable has a lower bound of zero, is positively skewed and has a long right tail. A lognormal distribution is commonly used to describe distributions of financial assets such as stock prices. It is also used in fitting claim amounts for automobile as well as health insurance. This is an example of another type of transformation which involves exponentiation.
Consider the transformation \(Y = e^{X}\), then the distribution function of \(Y\) is given by \[F_{Y}\left( y \right) = \Pr\left( Y \leq y \right) = \Pr\left( e^{X} \leq y \right) = \Pr\left( X \leq \ln y \right) = F_{X}\left( \ln y \right).\] Hence, the probability density function of interest \(f_{Y}(y)\) can be written as \[f_{Y}(y) = \frac{1}{y}f_{X}\left( \ln y \right).\]
Example 3.3.4. SOA Exam Question. \(X\) has a uniform distribution on the interval \((0,\ c)\). \(Y = e^{X}\). Find the distribution of \(Y\).
Show Example Solution
3.3.5 Finite Mixtures
Mixture distributions represent a useful way of modelling data that are drawn from a heterogeneous population. This parent population can be thought to be divided into multiple subpopulations with distinct distributions.
3.3.5.1 Two-point Mixture
If the underlying phenomenon is diverse and can actually be described as two phenomena representing two subpopulations with different modes, we can construct the two point mixture random variable \(X\). Given random variables \(X_{1}\) and \(X_{2}\), with probability density functions \(f_{X_{1}}\left( x \right)\) and \(f_{X_{2}}\left( x \right)\) respectively, the probability density function of \(X\) is the weighted average of the component probability density function \(f_{X_{1}}\left( x \right)\) and \(f_{X_{2}}\left( x \right)\). The probability density function and distribution function of \(X\) are given by \[f_{X}\left( x \right) = af_{X_{1}}\left( x \right) + \left( 1 - a \right)f_{X_{2}}\left( x \right),\] and \[F_{X}\left( x \right) = aF_{X_{1}}\left( x \right) + \left( 1 - a \right)F_{X_{2}}\left( x \right),\]
for \(0 < a <1\), where the mixing parameters \(a\) and \((1 - a)\) represent the proportions of data points that fall under each of the two subpopulations respectively. This weighted average can be applied to a number of other distribution related quantities. The k-th moment and moment generating function of \(X\) are given by \(\mathrm{E}\left( X^{k} \right) = a\mathrm{E}\left( X_{1}^{K} \right) + \left( 1 - a \right)\mathrm{E}\left( X_{2}^{k} \right)\), and \[M_{X}\left( t \right) = aM_{X_{1}}\left( t \right) + \left( 1 - a \right)M_{X_{2}}\left( t \right),\] respectively.
Example 3.3.5. SOA Exam Question. A collection of insurance policies consists of two types. 25% of policies are Type 1 and 75% of policies are Type 2. For a policy of Type 1, the loss amount per year follows an exponential distribution with mean 200, and for a policy of Type 2, the loss amount per year follows a Pareto distribution with parameters \(\alpha=3\) and \(\theta=200\). For a policy chosen at random from the entire collection of both types of policies, find the probability that the annual loss will be less than 100, and find the average loss.
Show Example Solution
3.3.5.2 k-point Mixture
In case of finite mixture distributions, the random variable of interest \(X\) has a probability \(p_{i}\) of being drawn from homogeneous subpopulation \(i\), where \(i = 1,2,\ldots,k\) and \(k\) is the initially specified number of subpopulations in our mixture. The mixing parameter \(p_{i}\) represents the proportion of observations from subpopulation \(i\). Consider the random variable \(X\) generated from \(k\) distinct subpopulations, where subpopulation \(i\) is modeled by the continuous distribution \(f_{X_{i}}\left( x \right)\). The probability distribution of \(X\) is given by \[f_{X}\left( x \right) = \sum_{i = 1}^{k}{p_{i}f_{X_{i}}\left( x \right)},\] where \(0 < p_{i} < 1\) and \(\sum_{i = 1}^{k} p_{i} = 1\).
This model is often referred to as a finite mixture or a \(k\)-point mixture. The distribution function, \(r\)-th moment and moment generating functions of the \(k\)-th point mixture are given as
\[F_{X}\left( x \right) = \sum_{i = 1}^{k}{p_{i}F_{X_{i}}\left( x \right)},\] \[\mathrm{E}\left( X^{r} \right) = \sum_{i = 1}^{k}{p_{i}\mathrm{E}\left( X_{i}^{r} \right)}, \text{and}\] \[M_{X}\left( t \right) = \sum_{i = 1}^{k}{p_{i}M_{X_{i}}\left( t \right)},\] respectively.
Example 3.3.6. SOA Exam Question. \(Y_{1}\) is a mixture of \(X_{1}\) and \(X_{2}\) with mixing weights \(a\) and \((1 - a)\). \(Y_{2}\) is a mixture of \(X_{3}\) and \(X_{4}\) with mixing weights \(b\) and \((1 - b)\). \(Z\) is a mixture of \(Y_{1}\) and \(Y_{2}\) with mixing weights \(c\) and \((1 - c)\).
Show that \(Z\) is a mixture of \(X_{1}\), \(X_{2}\), \(X_{3}\) and \(X_{4}\), and find the mixing weights.
Show Example Solution
3.3.6 Continuous Mixtures
A mixture with a very large number of subpopulations (\(k\) goes to infinity) is often referred to as a continuous mixture. In a continuous mixture, subpopulations are not distinguished by a discrete mixing parameter but by a continuous variable \(\theta\), where \(\theta\) plays the role of \(p_{i}\) in the finite mixture. Consider the random variable \(X\) with a distribution depending on a parameter \(\theta\), where \(\theta\) itself is a continuous random variable. This description yields the following model for \(X\) \[f_{X}\left( x \right) = \int_{0}^{\infty}{f_{X}\left( x\left| \theta \right.\ \right)g\left( \theta \right)} d \theta ,\] where \(f_{X}\left( x\left| \theta \right.\ \right)\) is the conditional distribution of \(X\) at a particular value of \(\theta\) and \(g\left( \theta \right)\) is the probability statement made about the unknown parameter \(\theta\), known as the prior distribution of \(\theta\) (the prior information or expert opinion to be used in the analysis).
The distribution function, \(k\)-th moment and moment generating functions of the continuous mixture are given as \[F_{X}\left( x \right) = \int_{-\infty}^{\infty}{F_{X}\left( x\left| \theta \right.\ \right)g\left( \theta \right)} d \theta,\] \[\mathrm{E}\left( X^{k} \right) = \int_{-\infty}^{\infty}{\mathrm{E}\left( X^{k}\left| \theta \right.\ \right)g\left( \theta \right)}d \theta,\] \[M_{X}\left( t \right) = \mathrm{E}\left( e^{t X} \right) = \int_{-\infty}^{\infty}{\mathrm{E}\left( e^{ tx}\left| \theta \right.\ \right)g\left( \theta \right)}d \theta, \] respectively.
The \(k\)-th moment of the mixture distribution can be rewritten as \[\mathrm{E}\left( X^{k} \right) = \int_{-\infty}^{\infty}{\mathrm{E}\left( X^{k}\left| \theta \right.\ \right)g\left( \theta \right)}d\theta = \mathrm{E}\left\lbrack \mathrm{E}\left( X^{k}\left| \theta \right.\ \right) \right\rbrack .\]
Using the Double Expectation Theorem we can define the mean and variance of \(X\) as \[\mathrm{E}\left( X \right) = \mathrm{E}\left\lbrack \mathrm{E}\left( X\left| \theta \right.\ \right) \right\rbrack\] and \[\mathrm{Var}\left( X \right) = \mathrm{E}\left\lbrack \mathrm{Var}\left( X\left| \theta \right.\ \right) \right\rbrack + \mathrm{Var}\left\lbrack \mathrm{E}\left( X\left| \theta \right.\ \right) \right\rbrack .\]
Example 3.3.7. SOA Exam Question. \(X\) has a normal distribution with a mean of \(\Lambda\) and variance of 1. \(\Lambda\) has a normal distribution with a mean of 1 and variance of 1. Find the mean and variance of \(X\).
Show Example Solution
Example 3.3.8. SOA Exam Question. Claim sizes, \(X\), are uniform on the interval \(\left(\theta,\theta+10\right)\) for each policyholder. \(\theta\) varies by policyholder according to an exponential distribution with mean 5. Find the unconditional distribution, mean and variance of \(X\).
Show Example Solution
3.4 Coverage Modifications
In this section we evaluate the impacts of coverage modifications: a) deductibles, b) policy limit, c) coinsurance and inflation on insurer’s costs.
3.4.1 Policy Deductibles
Under an ordinary deductible policy, the insured (policyholder) agrees to cover a fixed amount of an insurance claim before the insurer starts to pay. This fixed expense paid out of pocket is called the deductible and often denoted by \(d\). If the loss exceeds \(d\) then the insurer is responsible for covering the loss X less the deductible \(d\). Depending on the agreement, the deductible may apply to each covered loss or to the total losses during a defined benefit period (month, year, etc.)
Deductibles eliminate a large number of small claims, reduce costs of handling and processing these claims, reduce premiums for the policyholders and reduce moral hazard. Moral hazard occurs when the insured takes more risks, increasing the chances of loss due to perils insured against, knowing that the insurer will incur the cost (e.g. a policyholder with collision insurance may be encouraged to drive recklessly). The larger the deductible, the less the insured pays in premiums for an insurance policy.
Let \(X\) denote the loss incurred to the insured and \(Y\) denote the amount of paid claim by the insurer. Speaking of the benefit paid to the policyholder, we differentiate between two variables: The payment per loss and the payment per payment. The payment per loss variable, denoted by \(Y^{L}\), includes losses for which a payment is made as well as losses less than the deductible and hence is defined as \[Y^{L} = \left( X - d \right)_{+} = \left\{ \begin{array}{cc} 0 & X < d, \\ X - d & X > d \end{array} \right. .\] \(Y^{L}\) is often referred to as left censored and shifted variable because the values below \(d\) are not ignored and all losses are shifted by a value \(d\).
On the other hand, the payment per payment variable, denoted by \(Y^{P}\), is not defined when there is no payment and only includes losses for which a payment is made. The variable is defined as \[Y^{P} = \left\{ \begin{matrix} \text{Undefined} & X \le d \\ X - d & X > d \end{matrix} \right. \] \(Y^{P}\) is often referred to as left truncated and shifted variable or excess loss variable because the claims smaller than \(d\) are not reported and values above \(d\) are shifted by \(d\).
Even when the distribution of \(X\) is continuous, the distribution of \(Y^{L}\) is partly discrete and partly continuous. The discrete part of the distribution is concentrated at \(Y = 0\) (when \(X \leq d\)) and the continuous part is spread over the interval \(Y > 0\) (when \(X > d\)). For the discrete part, the probability that no payment is made is the probability that losses fall below the deductible; that is, \[\Pr\left( Y^{L} = 0 \right) = \Pr\left( X \leq d \right) = F_{X}\left( d \right).\] Using the transformation \(Y^{L} = X - d\) for the continuous part of the distribution, we can find the probability density function of \(Y^{L}\) given by \[f_{Y^{L}}\left( y \right) = \left\{ \begin{matrix} F_{X}\left( d \right) & y = 0, \\ f_{X}\left( y + d \right) & y > 0 \end{matrix} \right. \]
We can see that the payment per payment variable is the payment per loss variable conditioned on the loss exceeding the deductible; that is, \(Y^{P} = \left. \ Y^{L} \right|X > d\). Hence, the probability density function of \(Y^{P}\) is given by \[f_{Y^{P}}\left( y \right) = \frac{f_{X}\left( y + d \right)}{1 - F_{X}\left( d \right)},\] for \(y > 0\). Accordingly, the distribution functions of \(Y^{L}\)and \(Y^{P}\) are given by \[F_{Y^{L}}\left( y \right) = \left\{ \begin{matrix} F_{X}\left( d \right) & y = 0, \\ F_{X}\left( y + d \right) & y > 0. \\ \end{matrix} \right.\ \] and \[F_{Y^{P}}\left( y \right) = \frac{F_{X}\left( y + d \right) - F_{X}\left( d \right)}{1 - F_{X}\left( d \right)},\] for \(y > 0\), respectively.
The raw moments of \(Y^{L}\) and \(Y^{P}\) can be found directly using the probability density function of \(X\) as follows \[\mathrm{E}\left\lbrack \left( Y^{L} \right)^{k} \right\rbrack = \int_{d}^{\infty}\left( x - d \right)^{k}f_{X}\left( x \right)dx ,\] and \[\mathrm{E}\left\lbrack \left( Y^{P} \right)^{k} \right\rbrack = \frac{\int_{d}^{\infty}\left( x - d \right)^{k}f_{X}\left( x \right) dx }{{1 - F}_{X}\left( d \right)} = \frac{\mathrm{E}\left\lbrack \left( Y^{L} \right)^{k} \right\rbrack}{{1 - F}_{X}\left( d \right)},\] respectively.
We have seen that the deductible \(d\) imposed on an insurance policy is the amount of loss that has to be paid out of pocket before the insurer makes any payment. The deductible \(d\) imposed on an insurance policy reduces the insurer’s payment. The loss elimination ratio (LER) is the percentage decrease in the expected payment of the insurer as a result of imposing the deductible. LER is defined as \[LER = \frac{\mathrm{E}\left( X \right) - \mathrm{E}\left( Y^{L} \right)}{\mathrm{E}\left( X \right)}.\]
A little less common type of policy deductible is the franchise deductible. The franchise deductible will apply to the policy in the same way as ordinary deductible except that when the loss exceeds the deductible \(d\), the full loss is covered by the insurer. The payment per loss and payment per payment variables are defined as \[Y^{L} = \left\{ \begin{matrix} 0 & X \leq d, \\ X & X > d, \\ \end{matrix} \right.\ \] and \[Y^{P} = \left\{ \begin{matrix} \text{Undefined} & X \leq d, \\ X & X > d, \\ \end{matrix} \right.\ \] respectively.
Example 3.4.1. SOA Exam Question. A claim severity distribution is exponential with mean 1000. An insurance company will pay the amount of each claim in excess of a deductible of 100. Calculate the variance of the amount paid by the insurance company for one claim, including the possibility that the amount paid is 0.
Show Example Solution
Example 3.4.2. SOA Exam Question. For an insurance:
- Losses have a density function \[f_{X}\left( x \right) = \left\{ \begin{matrix} 0.02x & 0 < x < 10, \\ 0 & \text{elsewhere.} \\ \end{matrix} \right. \]
- The insurance has an ordinary deductible of 4 per loss.
- \(Y^{P}\) is the claim payment per payment random variable.
Calculate \(\mathrm{E}\left( Y^{P} \right)\).
Show Example Solution
Example 3.4.3. SOA Exam Question. You are given:
- Losses follow an exponential distribution with the same mean in all years.
- The loss elimination ratio this year is 70%.
- The ordinary deductible for the coming year is 4/3 of the current deductible.
Compute the loss elimination ratio for the coming year.
Show Example Solution
3.4.2 Policy Limits
Under a limited policy, the insurer is responsible for covering the actual loss \(X\) up to the limit of its coverage. This fixed limit of coverage is called the policy limit and often denoted by \(u\). If the loss exceeds the policy limit, the difference \(X - u\) has to be paid by the policyholder. While a higher policy limit means a higher payout to the insured, it is associated with a higher premium.
Let \(X\) denote the loss incurred to the insured and \(Y\) denote the amount of paid claim by the insurer. Then \(Y\) is defined as \[Y = X \land u = \left\{ \begin{matrix} X & X \leq u, \\ u & X > u. \\ \end{matrix} \right.\ \] It can be seen that the distinction between \(Y^{L}\) and \(Y^{P}\) is not needed under limited policy as the insurer will always make a payment.
Using the definitions of \(\left(X-d\right)_+ \text{ and } \left(X\land d\right)\), it can be easily seen that the expected payment without any coverage modification, \(X\), is equal to the sum of the expected payments with deductible \(d\) and limit \(d\). That is, \({X=\left(X-d\right)}_++ \left(X\land d\right)\).
When a loss is subject to a deductible d a limit u, the per-loss variable \(Y^L\) is defined as \[Y^{L} = \left\{ \begin{matrix} 0 & X \leq d, \\ \alpha\left( X - d \right) & d < X \leq u, \\ \alpha\left( u - d \right) & X > u. \\ \end{matrix} \right.\ \] Hence, \(Y^L\) can be expressed as \(Y^L=\left(X\land u\right)-\left(X\land d\right)\).
Even when the distribution of \(X\) is continuous, the distribution of \(Y\) is partly discrete and partly continuous. The discrete part of the distribution is concentrated at \(Y = u\) (when \(X > u\)), while the continuous part is spread over the interval \(Y < u\) (when \(X \leq u\)). For the discrete part, the probability that the benefit paid is \(u\), is the probability that the loss exceeds the policy limit \(u\); that is, \[\Pr \left( Y = u \right) = \Pr \left( X > u \right) = {1 - F}_{X}\left( u \right).\] For the continuous part of the distribution \(Y = X\), hence the probability density function of \(Y\) is given by \[f_{Y}\left( y \right) = \left\{ \begin{matrix} f_{X}\left( y \right) & 0 < y < u, \\ 1 - F_{X}\left( u \right) & y = u. \\ \end{matrix} \right.\ \] Accordingly, the distribution function of \(Y\) is given by \[F_{Y}\left( y \right) = \left\{ \begin{matrix} F_{X}\left( x \right) & 0 < y < u, \\ 1 & y \geq u. \\ \end{matrix} \right.\ \] The raw moments of \(Y\) can be found directly using the probability density function of \(X\) as follows \[\mathrm{E}\left( Y^{k} \right) = \mathrm{E}\left\lbrack \left( X \land u \right)^{k} \right\rbrack = \int_{0}^{u}x^{k}f_{X}\left( x \right)dx + \int_{u}^{\infty}{u^{k}f_{X}\left( x \right)} dx \\ = \int_{0}^{u}x^{k}f_{X}\left( x \right)dx + u^{k}\left\lbrack {1 - F}_{X}\left( u \right) \right\rbrack .\]
Example 3.4.4. SOA Exam Question. Under a group insurance policy, an insurer agrees to pay 100% of the medical bills incurred during the year by employees of a small company, up to a maximum total of one million dollars. The total amount of bills incurred, \(X\), has probability density function \[f_{X}\left( x \right) = \left\{ \begin{matrix} \frac{x\left( 4 - x \right)}{9} & 0 < x < 3, \\ 0 & \text{elsewhere.} \\ \end{matrix} \right.\ \] where \(x\) is measured in millions. Calculate the total amount, in millions of dollars, the insurer would expect to pay under this policy.
Show Example Solution
3.4.3 Coinsurance
As we have seen in Section 3.4.1, the amount of loss retained by the policyholder can be losses up to the deductible \(d\). The retained loss can also be a percentage of the claim. The percentage \(\alpha\), often referred to as the coinsurance factor, is the percentage of claim the insurance company is required to cover. If the policy is subject to an ordinary deductible and policy limit, coinsurance refers to the percentage of claim the insurer is required to cover, after imposing the ordinary deductible and policy limit. The payment per loss variable, \(Y^{L}\), is defined as \[Y^{L} = \left\{ \begin{matrix} 0 & X \leq d, \\ \alpha\left( X - d \right) & d < X \leq u, \\ \alpha\left( u - d \right) & X > u. \\ \end{matrix} \right.\ \] The policy limit (the maximum amount paid by the insurer) in this case is \(\alpha\left( u - d \right)\), while \(u\) is the maximum covered loss.
We have seen in Section 3.4.2 that when a loss is subject to both a deductible \(d\) and a limit \(u\) the per-loss variable \(Y^L\) can be expressed as \(Y^L=\left(X\land u\right)-\left(X\land d\right)\). With coinsurance, this becomes \(Y^L\) can be expressed as \(Y^L=\alpha\left[(X\land u)-(X\land d)\right]\).
The \(k\)-th moment of \(Y^{L}\) is given by \[\mathrm{E}\left\lbrack \left( Y^{L} \right)^{k} \right\rbrack = \int_{d}^{u}\left\lbrack \alpha\left( x - d \right) \right\rbrack^{k}f_{X}\left( x \right)dx + \int_{u}^{\infty}\left\lbrack \alpha\left( u - d \right) \right\rbrack^{k}f_{X}\left( x \right) dx .\]
A growth factor \(\left( 1 + r \right)\) may be applied to \(X\) resulting in an inflated loss random variable \(\left( 1 + r \right)X\) (the prespecified d and u remain unchanged). The resulting per loss variable can be written as \[Y^{L} = \left\{ \begin{matrix} 0 & X \leq \frac{d}{1 + r}, \\ \alpha\left\lbrack \left( 1 + r \right)X - d \right\rbrack & \frac{d}{1 + r} < X \leq \frac{u}{1 + r}, \\ \alpha\left( u - d \right) & X > \frac{u}{1 + r}. \\ \end{matrix} \right.\ \] The first and second moments of \(Y^{L}\) can be expressed as \[\mathrm{E}\left( Y^{L} \right) = \alpha\left( 1 + r \right)\left\lbrack \mathrm{E}\left( X \land \frac{u}{1 + r} \right) - \mathrm{E}\left( X \land \frac{d}{1 + r} \right) \right\rbrack,\] and \[\mathrm{E}\left\lbrack \left( Y^{L} \right)^{2} \right\rbrack = \alpha^{2}\left( 1 + r \right)^{2} \left\{ \mathrm{E}\left\lbrack \left( X \land \frac{u}{1 + r} \right)^{2} \right\rbrack - \mathrm{E}\left\lbrack \left( X \land \frac{d}{1 + r} \right)^{2} \right\rbrack \right. \\ \left. \ \ \ \ \ - 2\left( \frac{d}{1 + r} \right)\left\lbrack \mathrm{E}\left( X \land \frac{u}{1 + r} \right) - \mathrm{E}\left( X \land \frac{d}{1 + r} \right) \right\rbrack \right\} ,\] respectively.
The formulas given for the first and second moments of \(Y^{L}\) are general. Under full coverage, \(\alpha = 1\), \(r = 0\), \(u = \infty\), \(d = 0\) and \(\mathrm{E}\left( Y^{L} \right)\) reduces to \(\mathrm{E}\left( X \right)\). If only an ordinary deductible is imposed, \(\alpha = 1\), \(r = 0\), \(u = \infty\) and \(\mathrm{E}\left( Y^{L} \right)\) reduces to \(\mathrm{E}\left( X \right) - \mathrm{E}\left( X \land d \right)\). If only a policy limit is imposed \(\alpha = 1\), \(r = 0\), \(d = 0\) and \(\mathrm{E}\left( Y^{L} \right)\) reduces to \(\mathrm{E}\left( X \land u \right)\).
Example 3.4.5. SOA Exam Question. The ground up loss random variable for a health insurance policy in 2006 is modeled with X, an exponential distribution with mean 1000. An insurance policy pays the loss above an ordinary deductible of 100, with a maximum annual payment of 500. The ground up loss random variable is expected to be 5% larger in 2007, but the insurance in 2007 has the same deductible and maximum payment as in 2006. Find the percentage increase in the expected cost per payment from 2006 to 2007.
Show Example Solution
3.4.4 Reinsurance
In Section 3.4.1 we introduced the policy deductible, which is a contractual arrangement under which an insured transfers part of the risk by securing coverage from an insurer in return for an insurance premium. Under that policy, the insured must pay all losses up to the deductible, and the insurer only pays the amount (if any) above the deductible. We now introduce reinsurance, a mechanism of insurance for insurance companies. Reinsurance is a contractual arrangement under which an insurer transfers part of the underlying insured risk by securing coverage from another insurer (referred to as a reinsurer) in return for a reinsurance premium. Although reinsurance involves a relationship between three parties: the original insured, the insurer (often referred to as cedent or cedant) and the reinsurer, the parties of the reinsurance agreement are only the primary insurer and the reinsurer. There is no contractual agreement between the original insured and the reinsurer. Though many different types of reinsurance contracts exist, a common form is excess of loss coverage. In such contracts, the primary insurer must make all required payments to the insured until the primary insurer’s total payments reach a fixed reinsurance deducible. The reinsurer is then only responsible for paying losses above the reinsurance deductible. The maximum amount retained by the primary insurer in the reinsurance agreement (the reinsurance deductible) is called retention.
Reinsurance arrangements allow insurers with limited financial resources to increase the capacity to write insurance and meet client requests for larger insurance coverage while reducing the impact of potential losses and protecting the insurance company against catastrophic losses. Reinsurance also allows the primary insurer to benefit from underwriting skills, expertise and proficient complex claim file handling of the larger reinsurance companies.
Example 3.4.6. SOA Exam Question. In 2005 a risk has a two-parameter Pareto distribution with \(\alpha = 2\) and \(\theta = 3000\). In 2006 losses inflate by 20%. Insurance on the risk has a deductible of 600 in each year. \(P_{i}\), the premium in year \(i\), equals 1.2 times expected claims. The risk is reinsured with a deductible that stays the same in each year. \(R_{i}\), the reinsurance premium in year \(i\), equals 1.1 times the expected reinsured claims. \(\frac{R_{2005}}{P_{2005}} = 0.55\). Calculate \(\frac{R_{2006}}{P_{2006}}\).
Show Example Solution
3.5 Maximum Likelihood Estimation
In this section we estimate statistical parameters using the method of maximum likelihood. Maximum likelihood estimates in the presence of grouping, truncation or censoring are calculated.
3.5.1 Maximum Likelihood Estimators for Complete Data
Pricing of insurance premiums and estimation of claim reserving are among many actuarial problems that involve modeling the severity of loss (claim size). Appendix Chapter 17 reviews the definition of the likelihood function, introduces its properties, reviews the maximum likelihood estimators, extends their large-sample properties to the case where there are multiple parameters in the model, and reviews statistical inference based on maximum likelihood estimators. In this section, we present a few examples to illustrate how actuaries fit a parametric distribution model to a set of claim data using maximum likelihood. In these examples we derive the asymptotic variance of maximum-likelihood estimators of the model parameters. We use the delta method to derive the asymptotic variances of functions of these parameters.
Example 3.5.1. SOA Exam Question. Consider a random sample of claim amounts: 8,000 10,000 12,000 15,000. You assume that claim amounts follow an inverse exponential distribution, with parameter \(\theta\).- Calculate the maximum likelihood estimator for \(\theta\).
- Approximate the variance of the maximum likelihood estimator.
- Determine an approximate 95% confidence interval for \(\theta\).
- Determine an approximate 95% confidence interval for \(\Pr \left( X \leq 9,000 \right).\)
Show Example Solution
Example 3.5.2. SOA Exam Question. A random sample of size 6 is from a lognormal distribution with parameters \(\mu\) and \(\sigma\). The sample values are 200, 3,000, 8,000, 60,000, 60,000, 160,000.
- Calculate the maximum likelihood estimator for \(\mu\) and \(\sigma\).
- Estimate the covariance matrix of the maximum likelihood estimator.
- Determine approximate 95% confidence intervals for \(\mu\) and \(\sigma\).
- Determine an approximate 95% confidence interval for the mean of the lognormal distribution.
Show Example Solution
3.5.2 Maximum Likelihood Estimators for Grouped Data
In the previous section we considered the maximum likelihood estimation of continuous models from complete (individual) data. Each individual observation is recorded, and its contribution to the likelihood function is the density at that value. In this section we consider the problem of obtaining maximum likelihood estimates of parameters from grouped data. The observations are only available in grouped form, and the contribution of each observation to the likelihood function is the probability of falling in a specific group (interval). Let \(n_{j}\) represent the number of observations in the interval \(\left( \left. \ c_{j - 1},c_{j} \right\rbrack \right.\ \) The grouped data likelihood function is thus given by \[L\left( \theta \right) = \prod_{j = 1}^{k}\left\lbrack F\left( \left. \ c_{j} \right|\theta \right) - F\left( \left. \ c_{j - 1} \right|\theta \right) \right\rbrack^{n_{j}},\] where \(c_{0}\) is the smallest possible observation (often set to zero) and \(c_{k}\) is the largest possible observation (often set to infinity).
Example 3.5.3. SOA Exam Question. For a group of policies, you are given that losses follow the distribution function \(F\left( x \right) = 1 - \frac{\theta}{x}\), for \(\theta < x < \infty.\) Further, a sample of 20 losses resulted in the following:
\[ {\small \begin{matrix}\hline \text{Interval} & \text{Number of Losses} \\ \hline (\theta, 10] & 9 \\ (10, 25] & 6 \\ (25, \infty) & 5 \\ \hline \end{matrix} } \]
Calculate the maximum likelihood estimate of \(\theta\).
Show Example Solution
3.5.3 Maximum Likelihood Estimators for Censored Data
Another possible distinguishing feature of a data gathering mechanism is censoring. While for some events of interest (losses, claims, lifetimes, etc.) the complete data maybe available, for others only partial information is available; all that may be known is that the observation exceeds a specific value. The limited policy introduced in Section 3.4.2 is an example of right censoring. Any loss greater than or equal to the policy limit is recorded at the limit. The contribution of the censored observation to the likelihood function is the probability of the random variable exceeding this specific limit. Note that contributions of both complete and censored data share the survivor function, for a complete point this survivor function is multiplied by the hazard function, but for a censored observation it is not.
Example 3.5.4. SOA Exam Question. The random variable \(X\) has survival function: \[S_{X}\left( x \right) = \frac{\theta^{4}}{\left( \theta^{2} + x^{2} \right)^{2}}.\] Two values of \(X\) are observed to be 2 and 4. One other value exceeds 4. Calculate the maximum likelihood estimate of \(\theta\).
Show Example Solution
3.5.4 Maximum Likelihood Estimators for Truncated Data
This section is concerned with the maximum likelihood estimation of the continuous distribution of the random variable \(X\) when the data is incomplete due to truncation. If the values of \(X\) are truncated at \(d\), then it should be noted that we would not have been aware of the existence of these values had they not exceeded \(d\). The policy deductible introduced in Section 3.4.1 is an example of left truncation. Any loss less than or equal to the deductible is not recorded. The contribution to the likelihood function of an observation \(x\) truncated at \(d\) will be a conditional probability and the \(f_{X}\left( x \right)\) will be replaced by \(\frac{f_{X}\left( x \right)}{S_{X}\left( d \right)}\).
Example 3.5.5. SOA Exam Question. For the single parameter Pareto distribution with \(\theta = 2\), maximum likelihood estimation is applied to estimate the parameter \(\alpha\). Find the estimated mean of the ground up loss distribution based on the maximum likelihood estimate of \(\alpha\) for the following data set:- Ordinary policy deductible of 5, maximum covered loss of 25 (policy limit 20)
- 8 insurance payment amounts: 2, 4, 5, 5, 8, 10, 12, 15
- 2 limit payments: 20, 20.
Show Example Solution
3.6 Further Resources and Contributors
Contributors
- Zeinab Amin, The American University in Cairo, is the principal author of this chapter. Email: zeinabha@aucegypt.edu for chapter comments and suggested improvements.
- Many helpful comments have been provided by Hirokazu (Iwahiro) Iwasawa, iwahiro@bb.mbn.or.jp .
Exercises
Here are a set of exercises that guide the viewer through some of the theoretical foundations of Loss Data Analytics. Each tutorial is based on one or more questions from the professional actuarial examinations – typically the Society of Actuaries Exam C.
Bibliography
Venter, Gary. 1983. “Transformed Beta and Gamma Distributions and Aggregate Losses.” In Proceedings of the Casualty Actuarial Society, 70:289–308. 133 & 134.
McDonald, James B. 1984. “Some Generalized Functions for the Size Distribution of Income.” Econometrica: Journal of the Econometric Society. JSTOR, 647–63.
Cummins, J. David, and Richard A. Derrig. 2012. Managing the Insolvency Risk of Insurance Companies: Proceedings of the Second International Conference on Insurance Solvency. Vol. 12. Springer Science & Business Media.
Frees, Edward W., and Emiliano A. Valdez. 1998. “Understanding Relationships Using Copulas.” North American Actuarial Journal 2 (01): 1–25.
2008. “Hierarchical Insurance Claims Modeling.” Journal of the American Statistical Association 103 (484). Taylor & Francis: 1457–69.Klugman, Stuart A., Harry H. Panjer, and Gordon E. Willmot. 2012. Loss Models: From Data to Decisions. John Wiley & Sons.
Kreer, Markus, Ayşe Kizilersü, Anthony W Thomas, and Alfredo D Egídio dos Reis. 2015. “Goodness-of-Fit Tests and Applications for Left-Truncated Weibull Distributions to Non-Life Insurance.” European Actuarial Journal 5 (1). Springer: 139–63.
McDonald, James B, and Yexiao J Xu. 1995. “A Generalization of the Beta Distribution with Applications.” Journal of Econometrics 66 (1-2). Elsevier: 133–52.
Tevet, Dan. 2016. “Applying Generalized Linear Models to Insurance Data.” Predictive Modeling Applications in Actuarial Science: Volume 2, Case Studies in Insurance. Cambridge University Press, 39.